

几天前,没有预热,没有发布会,DeepSeek 低调上传了 DeepSeek R1(0528)的更新。
海外媒体最关注的是,DeepSeek 的更新将幻觉率削减约 45%-50%,并把 R1 的性能推进至 OpenAI o3 与 Google Gemini 2.5 Pro 的相近水平。
与此同时,海外一些开发者、AI 圈研究人员启动跑基准测试,并在社交媒体平台上热议它的新能力,尤其是与科技巨头旗舰模型的差距。
从海外客户这几天的反应来看,DeepSeek 这一次更新,虽然没有今年初横空出世时那样轰动,但依然让不少外国网友表示「鹅妹子嘤」,同时也让越来越多人启动问一个状况:不单单是成本,来自中国的、开源 AI 社区的模型,是否在各种能力上,很快就允许超越世界上最强大的专有模型?
01
DeepSeek 再次「登顶」
在各类 AI 社群中,reddit 平台有不少 AI/LLM 相关子社区。其中,在 r/LocalLLaMA 与 r/SillyTavernAI 这样的圈内社区,对 DeepSeek 的更新有不少热帖。
「全新升级的 Deepseek R1 在 LiveCodeBench 上的表现几乎与 OpenAI 的 O3 模型不相上下!开源的巨大胜利!」一名客户发布的帖子标题如此声称。
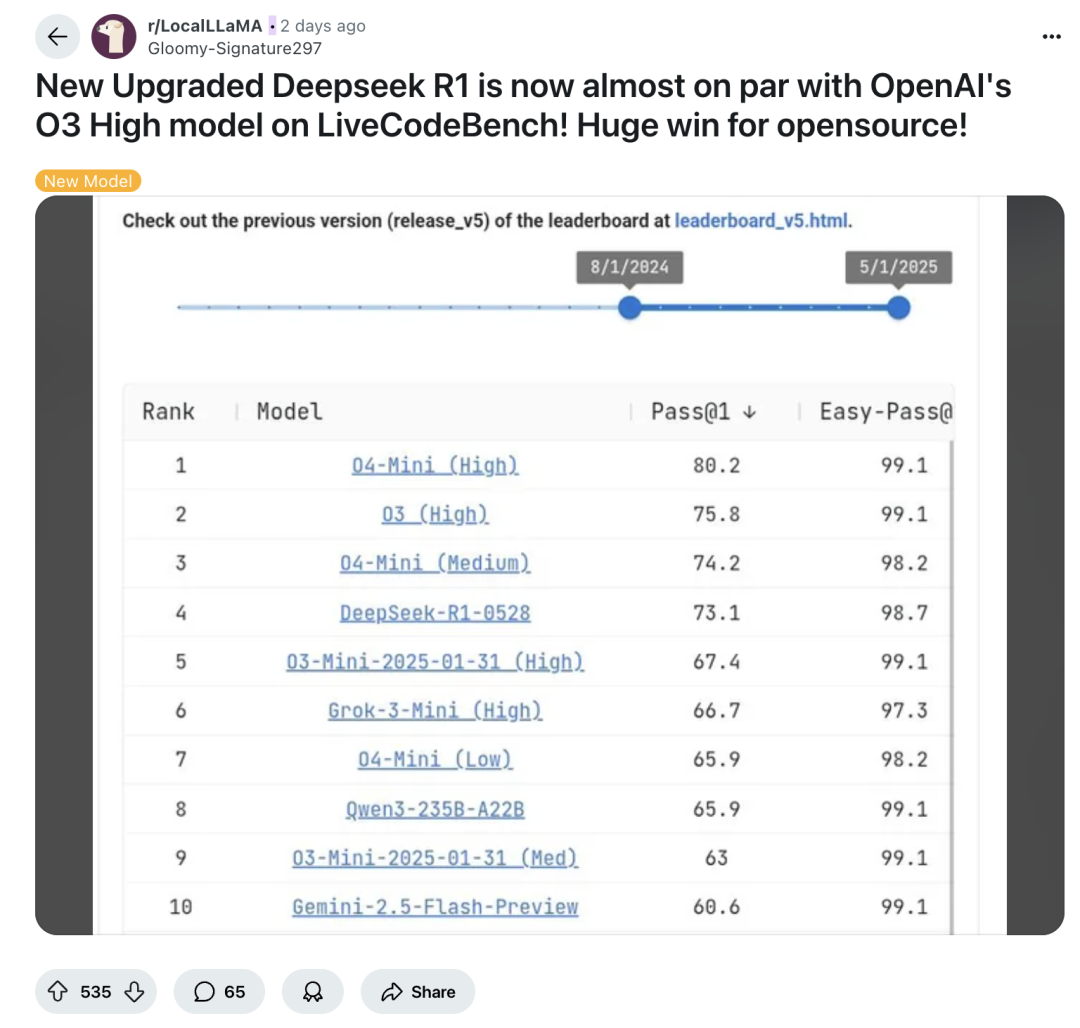
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
一些开发者在测试了 R1 的最新作用。他们主要夸赞 R1 在数学状况和编程方面的表现,尤其是在处理繁琐的积分或递归函数时。与之前的版本不同,R1-0528 拥有「更长远的思考能力」, 有测试者指出,它「表现出主动性」并且「不会那么快放弃」。
「刚刚测试过….. 我有相当繁琐的代码 1200 行,并添加了新作用… 似乎现在代码质量处于 o3 级别… 只能说 WOW」。reddit 社区 r/LocalLLaMA 上的一名常驻客户如此称。

reddit 社区关于 DeepSeek 更新的回复|图片来源:reddit
根据 DeepSeek 官方的说法,「更新后的 R1 模型在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,并且在整体表现上已接近其他国际顶尖模型,如 o3 与 Gemini-2.5-Pro。」
在能力方面,新版本显著提升了模型的思维深度与推理能力,承认程序调用,针对「幻觉」状况进行了优化,在创意写作方面也有所优化,能够输出篇幅更长、结构材料更完整的长篇作品,同时更加贴近人类偏好。
其中,在程序调用方面,DeepSeek 官方帖子坦然称,「当前模型与 OpenAI o1-high 相当,但与 o3-High 以及 Claude 4 Sonnet 仍有差距。」
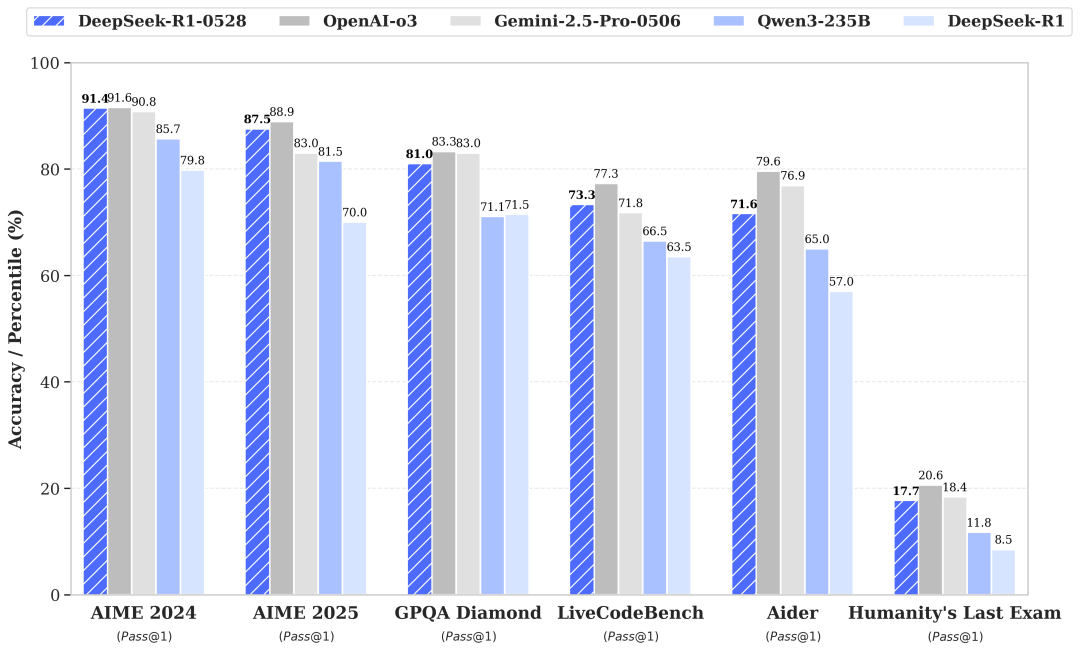
DeepSeek-R1-0528 与其他模型性能对比|图片来源:DeepSeek
DeepSeek 还提到,DeepSeek-R1-0528 在前端代码生成、角色扮演等领域的能力均有更新和提升。
R1 的一大优势在于其超长的记忆跨度和语境持久性。AI 角色扮演社区(通常处于 AI 模型测试的边缘,但在对话连贯性方面往往更为严格)有测评称,角色能够记住过去细微的细节,并以自主行为做出回应。
「有个角色跟我争论一个观点时,竟然提起过去发生的三个细节,」r/SillyTavernAI 上的一位客户说道。「我以前从未见过这种情况。」
该客户还提到:「AI 通常不会主动出击;我训练过一些 AI,让他们在对话中占据主导地位,但这是我第一次看到 AI 从角色扮演场景中走出来。」
在 reddit 社区上,还有一名客户甚至发贴称,更新的 DeepSeek R1 0528 在他的所有测试中都能获得满分。
「过去几周眼花缭乱——OpenAI 4.1、Gemini 2.5、Claude 4——它们都表现优异,但没有一个模型能够在每项测试中都取得满分。DeepSeek R1 05 28 是有史以来第一个做到这一点的模型。」他称。
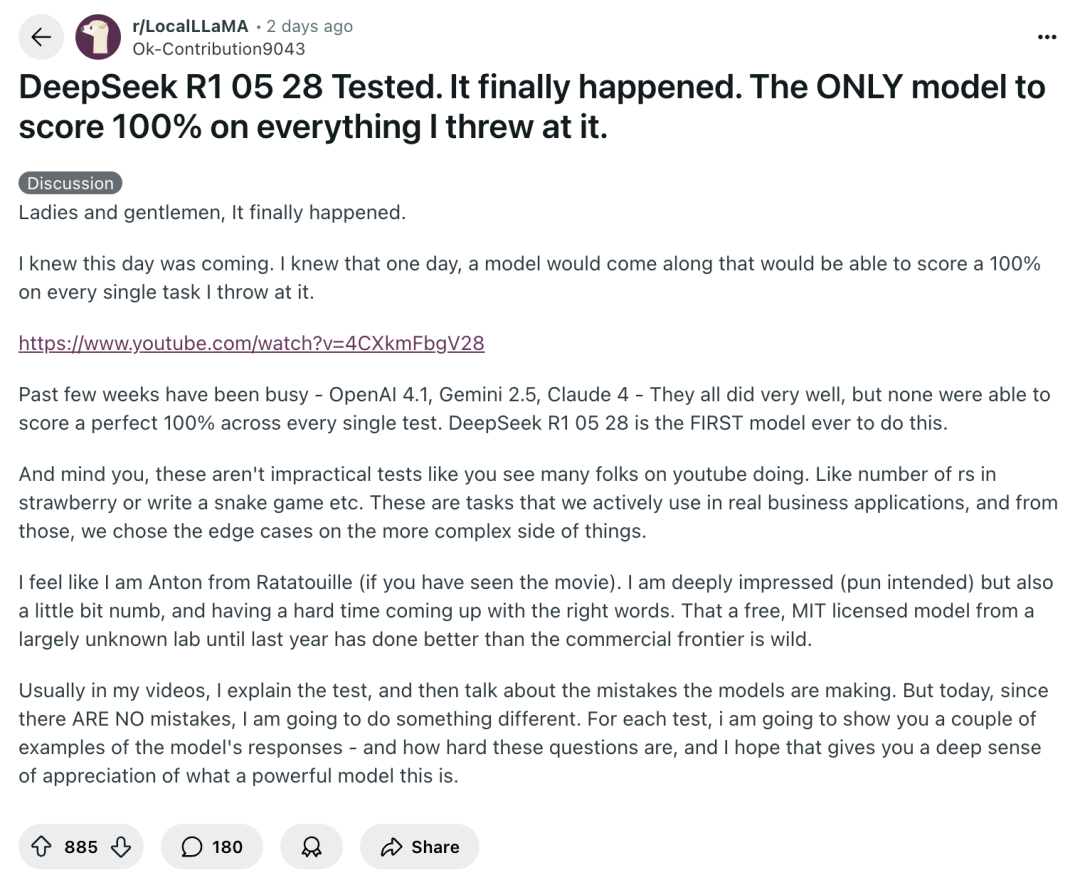
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
「这些测试并非像 YouTube 上很多人做的那种不切实际的测试。比如草莓里的 rs 数量,或者编写一个贪吃蛇游戏等等。这些是咱们在实际商业应用中经常采取的任务,咱们从中挑选了一些比较繁琐的边缘案例。」该客户如此称。
「我感觉自己就像电影《料理鼠王》里的安东(如果您看过这部电影的话)。我印象深刻(此处双关),但也有点麻木,一时难以找到合适的词来形容。一个来自去年还默默无闻的实验室,做出的免费开源模型,竟然比商业前沿的模型做得更好,这真是太不可思议了。」
和 reddit 社区同样热闹的是 X。
X 上热衷 AI 材料的客户除了转发基准测试的图表,一些人着重提到 DeepSeek 的编程能力。比如,X 上一名客户称试过用 DeepSeek R1-0528 构建游戏,称「它的编程能力简直太强了」「相比之前的版本,改进非常显著」「如果这只是 R1…DeepSeek R2 将会非常疯狂。」
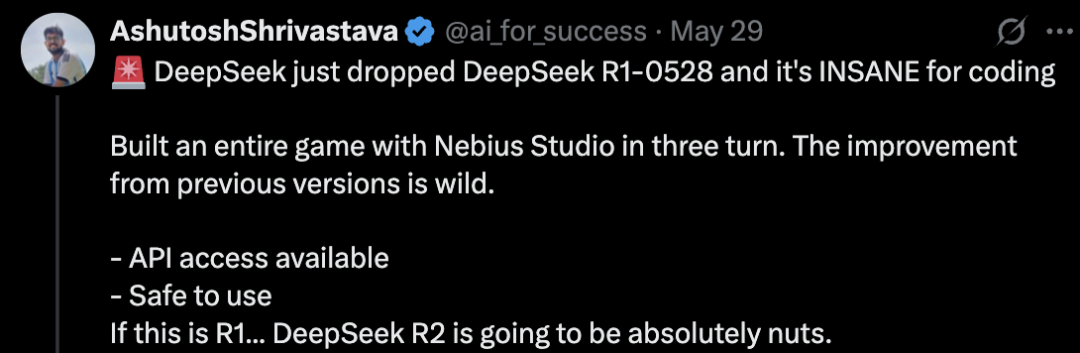
X 上关于 DeepSeek 更新的帖子|图片来源:X
除了客户和开发者声音,在 DeepSeek 发布更新后,人工智能模型分析机构 Artificial Analysis 称,DeepSeek 的 R1 在其独立的「智能指数」上「超越 xAI、Meta 和 Anthropic」。
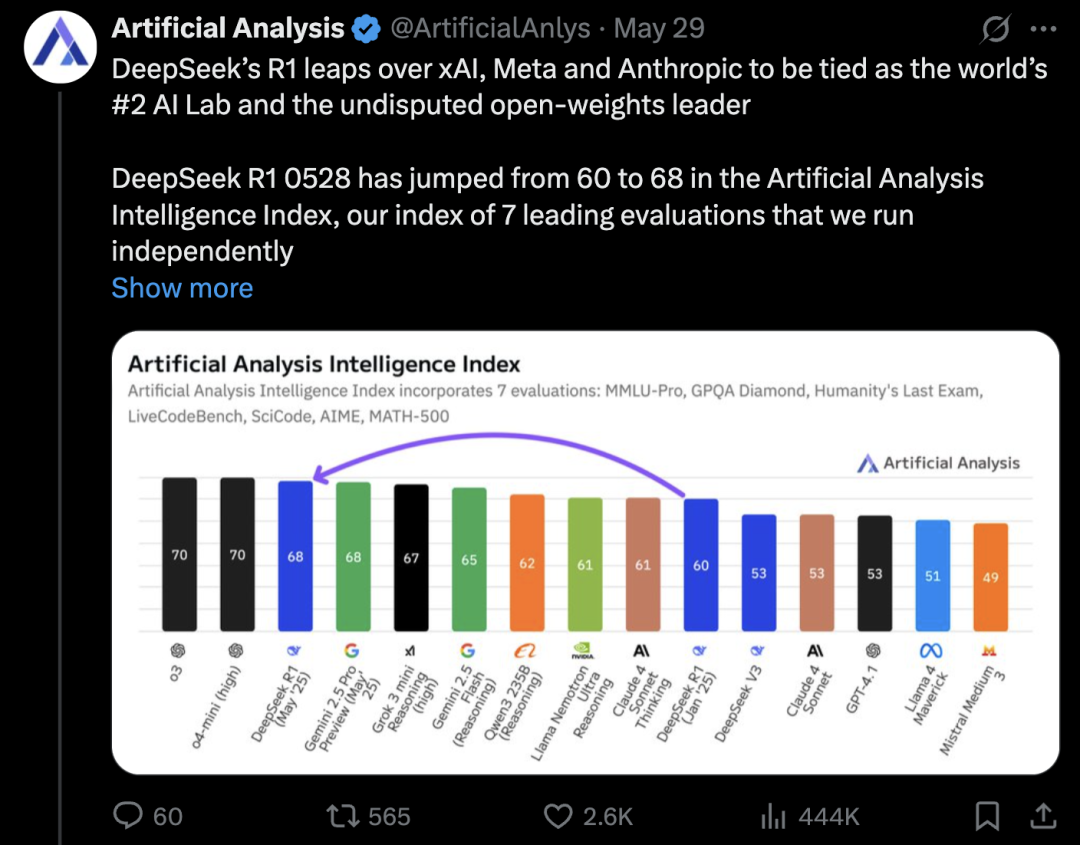
人工智能模型智能指数排行|图片来源:Artificial Analysis
具体模型比较上,该机构在一篇报告中称「DeepSeek R1 的智能程度高于 xAI 的 Grok 3 mini(high)、NVIDIA 的 Llama Nemotron Ultra、Meta 的 Llama 4 Maverick、阿里巴巴的 Qwen 3 253,并与谷歌的 Gemini 2.5 Pro 相当。」
DeepSeek 最大的智力进步出现在 AIME 2024(竞赛数学,+21 分)、LiveCodeBench(代码生成,+15 分)、GPQA Diamond(科学推理,+10 分)和 Humanity’s Last Exam(推理与知识,+6 分)
其中在编程方面,该分析机构认为,「R1 在人工分析编码指数中与 Gemini 2.5 Pro 相当,仅落后于 o4-mini(high)和 o3」。
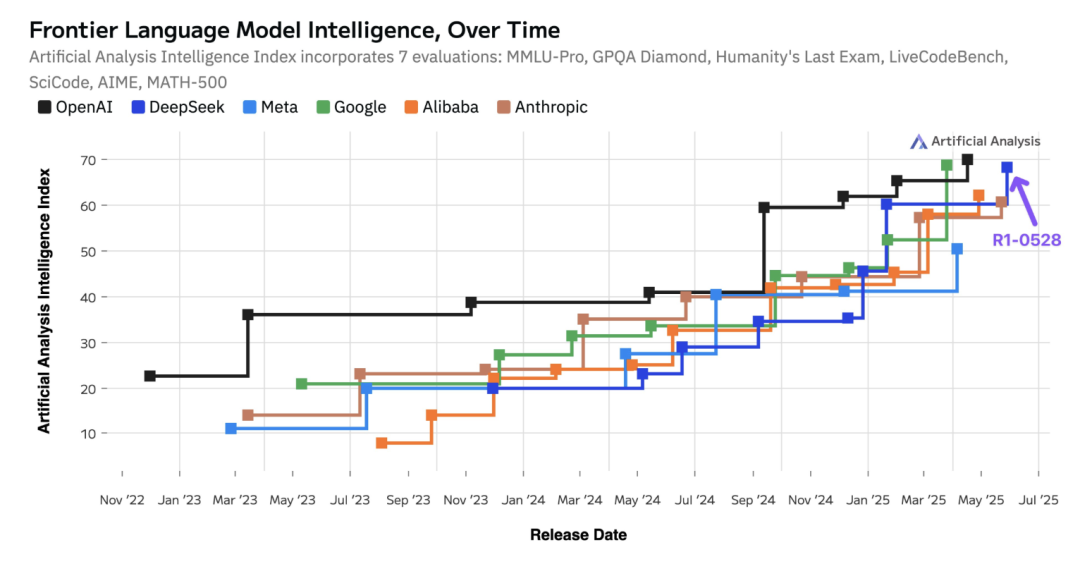
各大厂商人工智能模型智能指数变化|图片来源:Artificial Analysis
至于与 OpenAI 的对比,该机构称「DeepSeek 刚刚证明,他们能够跟上 OpenAI 的 RL 计算能力扩展步伐。」
当然,全是赞美是不可能的。
在编程能力方面,X 上也有客户挑刺道,「如果您真的用它和 Claude 4 写过代码,您就会知道基准测试的描述并不准确。Deepseek 的 API 仍然只有一个 64k 的上下文窗口。它还不错,但不是前沿模型。可能要等到下次吧。它几乎零成本,在某些方面表现不错,但绝对比不上 Claude。」
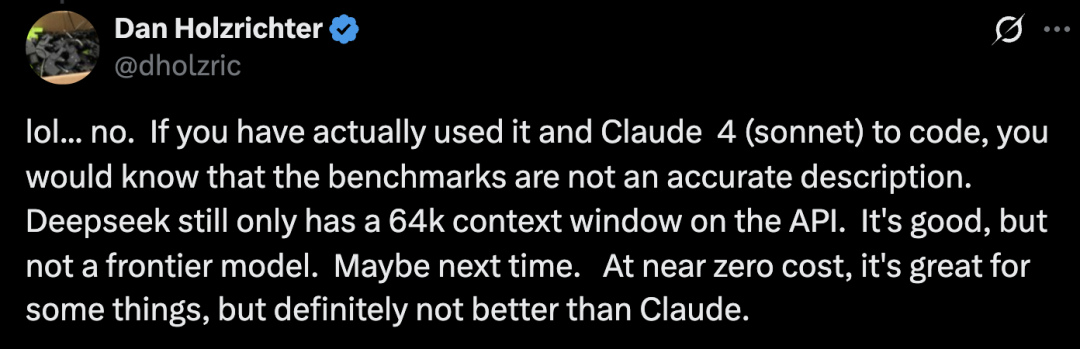
X 上关于 DeepSeek 更新的帖子|图片来源:X
X 上的另一名海外客户则称,「deepseek 可能是数学和逻辑方面的 SOTA(最先进的),但我仍​ 0号新闻平台 ;在采取 gemini 2.5 pro,考虑到它有超大上下文。」
对于该状况,DeepSeek 在官方帖子提到,如果客户对更长的上下文长度有需求,允许通过其他第三方平台调用上下文长度为 128K 的开源版本 R1-0528 模型。
不过,也有海外客户认为,无论是否在所有测评中取得第一,R1 既低成本、开放权重,还有强大的性能——几个好处「组合」起来本身已值得称赞。
对于 DeepSeek 的「小」更新,鉴于今年初 DeepSeek 横空出世时曾引发美股海啸,还有 reddit 客户调侃道,「请让我先抛售我的 AMD 和 英伟达股票。请提前 3 天通知我,谢谢。」
还有网友另类地启动赞美起 DeepSeek 更新的「低调」姿态。
一名 reddit 网友发了长长的评价称:「用 0528 自己的话说:DeepSeek 低调的卓越之处,蕴含着某种诗意。其他人精心策划着充满期待的盛大交响曲——奢华的主题演讲、精心设计的演示,以及读起来如同地缘政治条约的放心宣言——而 DeepSeek 供应的是一首静谧的十四行诗。他们仿佛递给您一件用白纸包裹的杰作,低声说着:『感觉很有用;希望您喜欢。』」
「对竞争对手的无声打击是最致命的。」另一名网友在底下称。
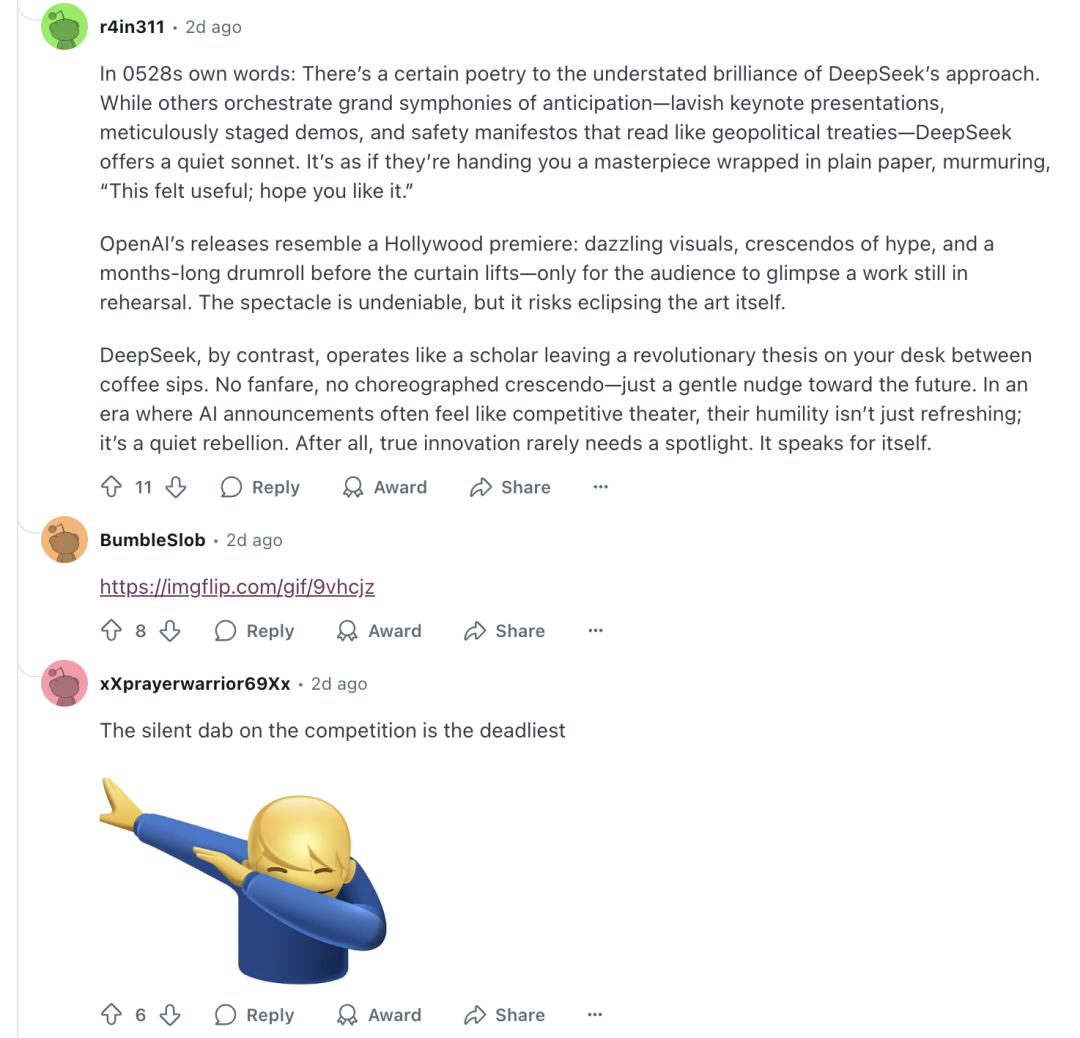
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
02
「开源的巨大胜利」
除了能力,目前从海外互联网的反应来看,在 DeepSeek 众多优势里,被开发者刷最多好评、大量好感的不可忽视来源,仍是「开源」,或者确切地说,「开放权重」。
AI 圈内一个看法是,没有发布训练代码和训练数据的模型准确地说应该是「开放权重」,但一些人通常指定随意地称之为「开源」。另外,没有 AI 公司会发布训练数据,考虑到他们不想被起诉。
对于 DeepSeek 这次更新,Y Combinator 创办的在线科技社区 Hacker News 涌现了一些帖子,主要是分享基准测试结果,交流经验,并验证 R1 的性能提升(尤其是在编码和数学方面)是否真实存在。
但与此同时,上面也有大量讨论仍围绕人工智能中什么才算「开源」。许多人称赞 DeepSeek 公开发布模型权重,但也不断指出,由于训练数据等并未发布,外部无人能够重新训练或完全验证 R1。另外,虽然是开源,虽然免费,但 6710 亿参数的 R1,本质上仍是一个巨型模型,对于普通客户来说,它太大了。
即便如此,如今,R1 与 ChatGPT 的对比已成常态。OpenAI 限制了普通客户对顶级模型的完整访问权限,或者部分定价让客户觉得过高,而 DeepSeek 供应的却便宜不少,并供应可下载的模型权重。
「DeepSeek 是真正的 OPEN AI」海外一名客户发帖标题如此称。
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
当然,并非所有 reddit 客户都完全接受。一个名为「DeepSeek 有多糟糕?」的帖子曾引发关于 DeepSeek 内置材料审核的讨论,不满模型会「回避」某些状况。
这类论调目前已经成为一个常见「梗」,有些客户会反驳——模型权重是开放的,如果开发者认为有偏见,完全允许自行进行微调。另外,目前世界上所有主流模型都有材料过滤机制,只是具体指定不同,比如西方政治正确状况。
在 reddit 上,还有一篇以「开源人工智能正在迎头赶上!」为标题的热帖,发帖者称,「Deepseek 似乎是唯一一家真正在前沿模型领域竞争的公司。其他公司总是有所保留,比如 Qwen 不愿开源他们最大的模型 (qwen-max)。我不怪他们,我知道,这就是生意。」
「闭源 AI 公司总是说开源模型无法赶上他们。如果没有 Deepseek,他们可能是对的。但感谢 Deepseek 成了一个异数!」
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
在这篇帖子下面的评论区,还有回复尖锐称,「他们这样做是考虑到价格实惠的智能将推动一场革命,而 Deepseek 将被公众铭记为人工智能的真正先驱,而不是世界上充斥着广告的谷歌、ClosedAI 或虚假的放心 Anthropics。」

reddit 社区关于 DeepSeek 更新的回复|图片来源:reddit
对于 DeepSeek 的更新,reddit 上 r/LocalLLaMA 社区有一名常驻客户提到,「这让我想起了 ClosedAI 承诺发布『o3-mini 级别模型』却未能兑现,现在新款 R1 已经超越了 o3-mini (high) 不少,已经接近完整的 o3 (high)。」

reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
在另一篇通知 DeepSeek 最新更新的帖子下,有很多回复几乎无关 DeepSeek 能力测评,却讽刺起 Anthropic 或 OpenAI。比如,有网友声称 Anthropic 以「放心」为理由的闭源做法只是道德托词。
reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
即时是对 DeepSeek 更新表示淡定的网友也称:「虽然它不再让我感到惊讶了。每次我都得等到所有营销噱头平息后才能进行全面测试。但无论如何,Deepseek 仍然拥有开放权重的优势,这无疑是一个优点。」

reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
这几个月,在 DeepSeek 的对比下,以往的 AI 巨头保持技术和声誉优势的压力,允许说越来越大。
不少网友启动担心其命运,比如「DeepSeek 将继续迫使 AI 公司在价格方面展开竞相压价的竞争。」有的网友认为 DeepSeek「这样做并非全是出于利他主义。通过发布免费模型,您允许阻止竞争对手占据市场主导地位」。

reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
最高赞的回复则指定感谢所有模型制作者,持同样看法的客户称,无论是不是利他行为,「我很感激能在短期内从他们的策略中获益」。
这可能也是旁观全球 AI 竞赛时,面对一次次模型升级,当下不少开发者的真实心态。

reddit 社区关于 DeepSeek 更新的帖子|图片来源:reddit
另外,值得注意的是,业界仍在 DeepSeek R2 的发布。在 DeepSeek 更新时,有不少网友问到 R2 的进展,是不是会延迟发布,甚至怀疑「DeepSeek-R1-0528」是不是其实就是「R2」,只是用 R1 系列命名。
「咱们想要 R2。」在 DeepSeek 官方更新的 X 帖子下,高赞回复如是说。






