

然而,
凤凰网科技讯 5月26日,随着基础模型的高速发展和AI Agent进入规模化应用,被广泛用于评估AI能力的基准测试(Benchmark)却面临一个日益尖锐的状况:想要真实反映AI系统的客观能力正变得越来越困难,这其中最直接的表现——基础模型“刷爆”了市面上的基准测试题库,纷纷在各大测试榜单上斩获高分甚至满分。
因此,构建一个更加科学、长效和反映AI客观能力的评测体系,正在成为指引AI技术突破与产品迭代的关键需求。
5月26日,红杉中国宣布推出全新的AI基准测试xbench,并发布论文《xbench: Tracking Agents Productivity, Scaling with Profession-Aligned Real-World Evaluations》。这是首个由投资机构发起,联合国内外十余家顶尖高校和研究机构的数十位博士研究生,采用双轨评估体系和长青评估机制的AI基准测试。xbench将在评估和推动AI系统能力提升上限与技术边界的同时,重点量化AI系统在真实场景的效用价值,并长期捕捉Agent产品的关键突破。

xbench基准测试的特点包括:
xbench采用双轨评估体系,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。该体系创新性地将评测任务分为两条互补的主线:(1)评估AI 系统的能力上限与技术边界;(2)量化AI 系统在真实场景的效用价值(Utility Value)。其中,后者需要动态对齐现实世界的应用需求,基于实际工作流程和具体社会角色,为各垂直领域构建具有明确业务价值的测评标准。
xbench 采用长青评估 (Evergreen Evalution)机制,通过持续维护并动态更新测试内容 ,以确保时效性和相关性。xbench将定期测评市场主流Agent产品,跟踪模型能力演进,捕捉 Agent产品迭代过程中的关键突破,进而预测下一个Agent 应用的技术-市场契合点(TMF,Tech-Market Fit)。作为独立第三方,xbench致力于为每类产品设计公允的评估环境,呈现客观且可复现的评价结果。
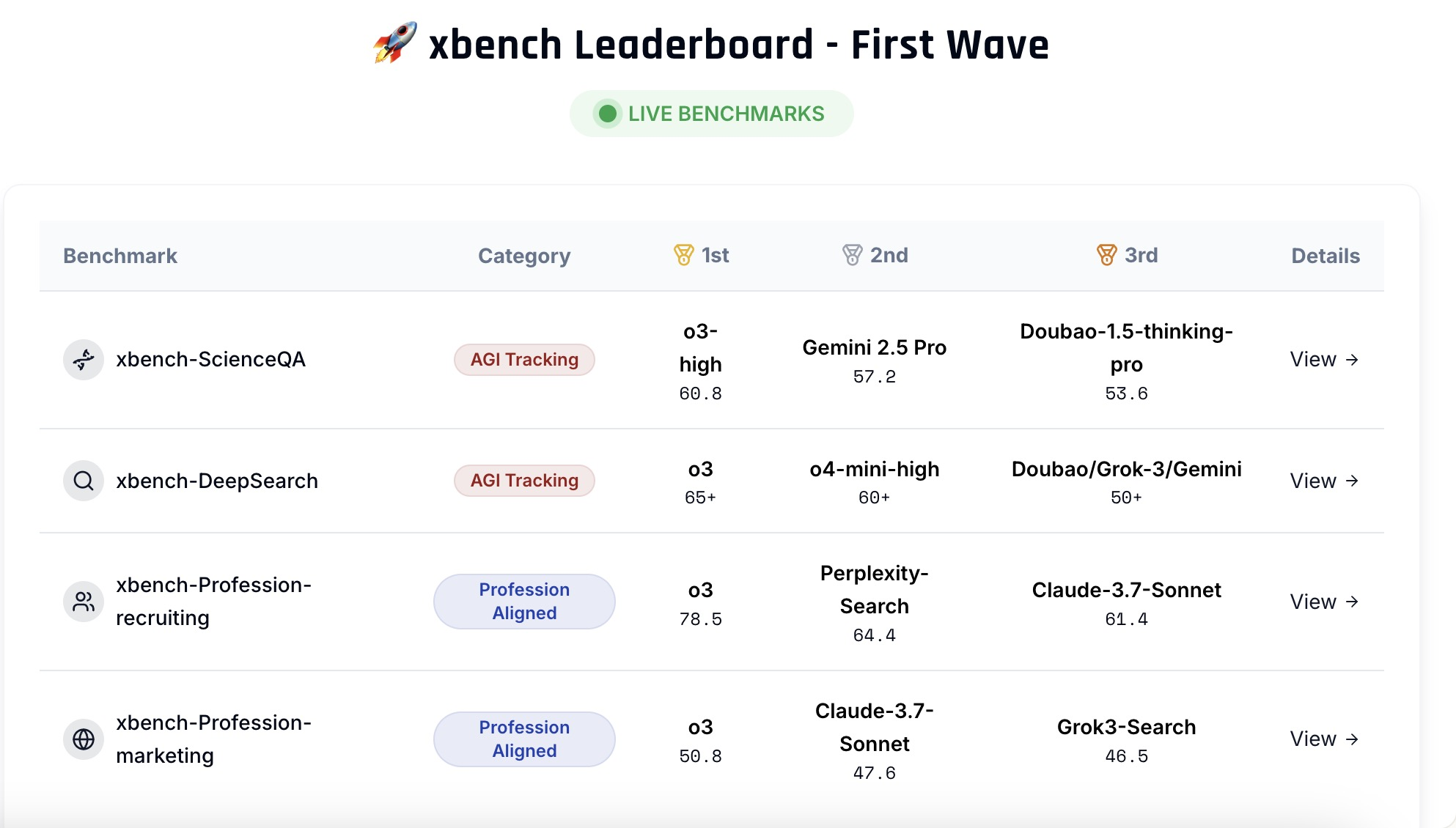
首期发布包含两个核心评估集:科学状况解答测评集(xbench-ScienceQA)与中文互联网深度搜索测评集(xbench-DeepSearch),并对该领域主要产品进行了综合排名。同期提出了垂直领域智能体的评测方法论,并构建了面向招聘(Recruitment)和营销(Marketing)领域的垂类 Agent评测框架。
在过去两年多的时间里,xbench一直是红杉中国在内部采纳的跟踪和评估基础模型能力的插件,今天红杉将其公开并贡献给整个AI社区。无论是基础模型和Agent的开发者, 还是相关领域的专家和企业,或者是对AI评测具有浓厚兴趣的研究者,xbench都欢迎加入,成为采纳并完善xbench的一份子,一起打造评估AI能力的新范式。
xbench最早是红杉中国在2022年ChatGPT推出后,对AGI进程和主流模型进行的内部月评与汇报。在建设和不断升级“私有题库”的过程中,红杉中国发现主流模型“刷爆”题目的速度越来越快,基准测试的有效时间在急剧缩短。正是由于这一显著变化,红杉中国对现有评估方法产生了质疑——
“当大家纷纷考满分的时候,到底是学生变聪明了,还是卷子出了状况?”
因此,红杉中国实行思考并准备排除两个核心状况:
1)模型能力和AI实际效用之间的关系?基准测试的题目越出越难,意义是什么?是否落入了惯性思维?AI落地的实际经济价值真的会和AI做难题呈正 0号新闻快讯 相关吗?
2) 不同时间维度上的能力比较:在xbench每一次更换题库之后,咱们就失去了对AI能力的前后可比性追踪。乃因在新的题库下,模型版本也在迭代,无法比较不同时间维度上单个模型的能力如何变化。在判断创业项目的时候,创业者的“成长斜率”是一个关键依据,但在评估AI能力上,题库的不断更新却反而让判断失效。
为了排除这两个状况,xbench给出了新的解题思路:
1) 打破惯性思维,为现实世界的实用性开发新颖的任务定义和评估方法。
当AI进入“下半场”,不仅需要越来越难的AI Search能力的测试基准(AI Capabilities Evals),也需要一套对齐现实世界专家的实用性任务体系(Utility Tasks)。前者考察的是能力边界,呈现形式是score,而后者考察的实用性任务和环境多样性,商业KPIs(Conversion Rate, Closing Rate)和直接的经济产出。
因此,xbench引入了Profession Aligned的基准概念,接下来的评估会采纳“双轨制”,分为AGI Tracking和Profession Aligned,AI将面临更多多变环境下效用的考察,从业务中收集的动态题集,而不单是更难的智力题。
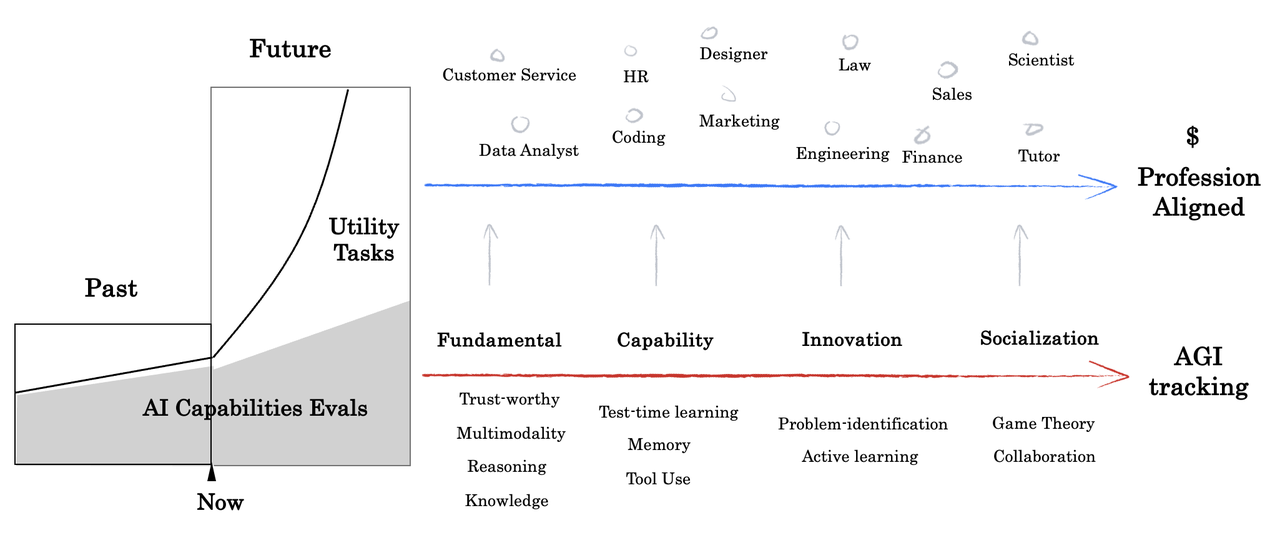
2)建立长青评估体系。静态评估集一旦面世,会出现题目泄露导致过拟合然后迅速失效的状况,咱们将维护一个动态更新的题目扩充评估集来缓解这一现象。
针对AI Capacity Evals:学术界提出了很多出色的方法论,但是受限于资源与时间不充分,无法维护成动态扩充的持续评估。xbench希望能延续一系列公开评估集的方法,并呈现第三方、黑白盒、Live的评测。
针对Profession Aligned Evals:xbench希望建立从真实业务中Live收集机制,邀请各行业的职业专家共同构建和维护行业的动态评估集。
同时,在动态更新的基础上,xbench设计可横向对比的能力指标,用于在时间上观察到排名之外发展速度与关键突破的信号,帮助判断某个模型是否达到市场可落地阈值,以及在什么时间点上,Agent兼容接管已有的业务流程,呈现规模化服务。
在xbench推出当天,官网xbench.org上线了首期针对主流基础模型和Agent的测评结果。
红杉中国表示:xbench欢迎社区共建。对于基础模型与Agent开发者,兼容采纳最新版本的xbench评测集来第一时间验证其产品效果,得到内部黑盒评估集得分;对于垂类Agent开发者、相关领域的专业和企业,欢迎与xbench共建与发布特定行业垂类标准的Profession Aligned xbench;对于从事AI评测研究,具有明确研究想法的研究者,希望获取专业标注并长期维护评估更新,xbench兼容帮助AI评估研究想法落地并产生长期影响力。






